Bu yazıda bir sql’i tune edip sorgu sonucunun hızlandırılması konusunda index ekleme yöntemini açıklayacağım. Burada anlatacağım yöntemi oracle, postgresql, mysql ve diğer veritabanlarında kullanabilirsiniz.
İlk olarak index nedir ve neden eklenmesi gerektiğini açıklamak istiyorum. İndex oluşturulmuş bir ağaç yapısıdır ve birden çok index türü vardır. B-tree index yapısını aşağıdaki şekilde inceleyebilirsiniz. Leaf block dediğimiz yerde ilgili tablonun içerisindeki rowların id leri bulunmaktadır. Bunu adres olarak düşünebiliriz. Branch blocks dediğimiz yer ise datanın belirli bir düzene göre gruplandığı yerdir. Aşağıdaki resimde görebileceğiniz gibi job_id kolonunda 2 değerine sahip satırların id numaraları bir blokta tutulmuş. Bu da job_id = 2 koşulu istendiğinde tabloyu full okumak yerine sadece ilgili bloklara gidip okuma yapacağı anlamına gelmektedir.
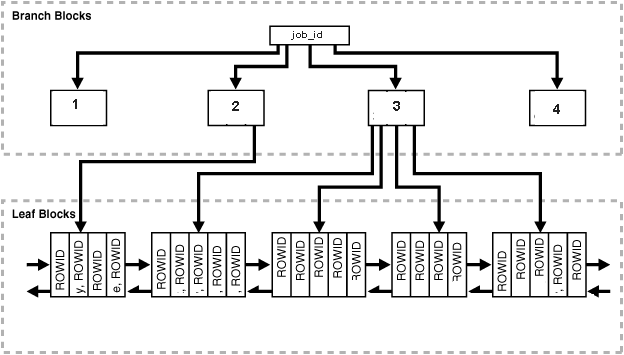
Tablo full okunmadığı için ilgili sql daha hızlı sonuç üretecektir. Daha hızlı sonuç üretmesi veritabanının fazla efor harcamamasına ve daha performanslı çalışmasına neden olacaktır.
Çok fazla transaction alan veritabanlarında sql’lerin sorgu sonuç süreleri kritik bir öneme sahiptir. Şu şekilde bir hesap yapacak olursak daha anlaşılır olacaktır. Elimizde çalışması 1 sn süren bir sql olsun ve bu sql uygulamadan veritabanına 10 bin kez gönderilsin. Bu işlem veritabanında 1 sn* 10 bin kez çalışacaktır ve veritabanını toplamda 10 bin saniye / 60 = 166 dakika meşgul edecektir. Tabi cpu’nun saniye de milyarlarca işlem yapabildiği için gerçek hayatta bu işlem 166 dakikada sürmeyecektir.
İlgili sql’e index ekleyip çalışma süresini yarıya düşürdüğümüzü varsayarsak toplamda 83 dakika kazanmış olacağız ki bu muazzam bir süre. Bu örnekte saniyeler üzerinden gidiyorum fakat sql’lerin veritabanında çalışma süreleri mili saniyeleri geçmemesi gerekiyor. 0.5 saniye bile bir sorgu için aşırı büyük bir değer.
Şimdi veritabanının bir sorguyu çalıştırırken sonucu getirmek için izlediği yolu göstereceğim. Örnek olarak elimizde aşağıdaki gibi bir sql sorgusu olsun.
select firts_name, last_name from hr.employee where job_id = 2;
Bu sql’i veritabanı şu şekilde yorumlayacaktır:
– job_id kolonunda değeri 2 olan
– hr.employee tablosundaki
– first_name ve last_name kolonundaki tüm verileri getir.
Sorgu bizim aksimize tersten okunarak istenilen dataları getirmek için işlenmeye başlandı. Bu kısımda job_id kolonunda 2 değerine sahip satırlar için tabloyu satır satır okuyup eşleşen kayıtları bulmaya çalışacaktır. İlgili kolonda eğer bir index yok ise explain plan da aşağıda da görebileceğiniz gibi “full table access” yöntemi kullanılacaktır.
| OPERATION | OPTIONS | OBJECT_NAME | POSITION |
|---|---|---|---|
| SELECT STATEMENT | – | – | 2 |
| ..TABLE ACCESS | TABLE ACCESS FULL | EMPLOYEES | 1 |
Eğer employees tablosunun job_id kolonunda bir index olmuş olsaydı tabloyu full okumak zorunda kalmayacak ve explain plan’ı aşağıdaki gibi olacaktı.
| OPERATION | OPTIONS | OBJECT_NAME | POSITION |
|---|---|---|---|
| SELECT STATEMENT | – | – | 2 |
| ..TABLE ACCESS | INDEX RANGE SCAN | EMPLOYEES | 1 |
Şekilde görüldüğü gibi index range scan yöntemi ile tabloya yapılan erişim sorgu maliyetini düşürmektedir. Elinizdeki sql’leri bu doğrultuda inceleyerek gerekli olabilecek indexleri oluşturabilirsiniz.
Son olarak aşağıdaki gibi bir sql’i ele alalım.
select firts_name, last_name from hr.employee where job_id = 2 and first_name = 'Emrah';
Bu sqli çalıştırırken job_id kolonunda index olmasına rağmen sorgu çalıştırıldığında ilgili index kullanılmayabilir. Bu durumda bileşik index oluşturulması gerekir. İlk oluşturulan basit index tipini ifade etmekteydi. Bu durumda bileşik index oluşturmak zorunda kalınabilirdi. Oracle veritabanında basit ve bileşik index aşağıdaki gibi oluşturulabilir.
# basit index create index [index_name] on [table_name] (column); # bileşik index create index [index_name] on [table_name] (column1,column2);